(请保留->发布地址: http://yiiyee.cn/blog/author/luobing/ )
我当年学习UEFI的最终目标是实现UEFI Oprom,写入PCI-E ROM,作为隔离卡的底层软件运行。中间的一个目标是编写UEFI driver/application,与bios一起编译,同样是作为底层软件,与另外一款卡通讯。当时是与联想共同开发了一款安全隔离计算机,中间目标就是为这款产品而设的。
最后两个目标都实现了,当年刚做的时候还是比较辛苦的。第一个面临的问题就是使用哪种程序入口。有三种可选:UefiMain,main,ShellAppMain。
参照当时能找到的资料,《Beyond BIOS》、《Harnessing the UEFI Shell》以及UEFI spec(当年看的是2.3,现在都到2.9了),还有bios之家、网友的博客,终于摸到了一些门径。
图1 曾经使用过的参考资料 当年的我并不了解这些程序入口的区别,是最近写博客的时候看《UEFI原理与编程》时才有所了解(终于有本中文版的参考资料了!感谢作者戴正华,有机会真想拜见)。
我的理解,main和ShellAppMain肯定是不能用在Option ROM上的。那么多的链接库,一是没法放进去,二是即便可以放进去,工作量也太大了。简单来说,就如同我之前开发的Legacy Option ROM一样,只能调用int 10h,int 13h,int 16h等这些bios中断,想调用int 33h这些DOS中断,你只能把整个DOS弄进去(更别提那个时候可能BIOS都还没准备好,放进去也运行不了)。
不过,使用main的程序入口,可以很方便的进行Shell下的测试。所以在实现这第一个程序的时候,我选择了这种编译方式。
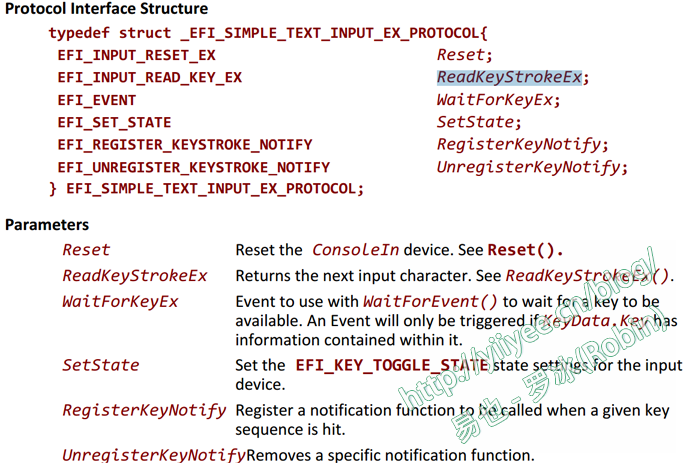
如图,使用的是以下的API(UEFI spec 2.8 Page431):
图2 访问键盘所用API API还是很好理解的,看EFI_KEY_DATA的数据结构,与int 16h 0号功能返回的是一样的。我不知道UEFI是怎么处理硬件中断9的,估计也是封装在了这些API中。
程序编写相对比较容易,gBS和gST是预置的,直接使用就可以了。(代码在文末提供下载地址)根据API的说明,我编写了一个获取键盘输入的函数GetKeyEx,将用户输入的键盘信息保存下来。
上述的工作相对比较简单,有点麻烦的是准备编译。使用main函数的工程模块需要在AppPkg环境下才能成功编译。
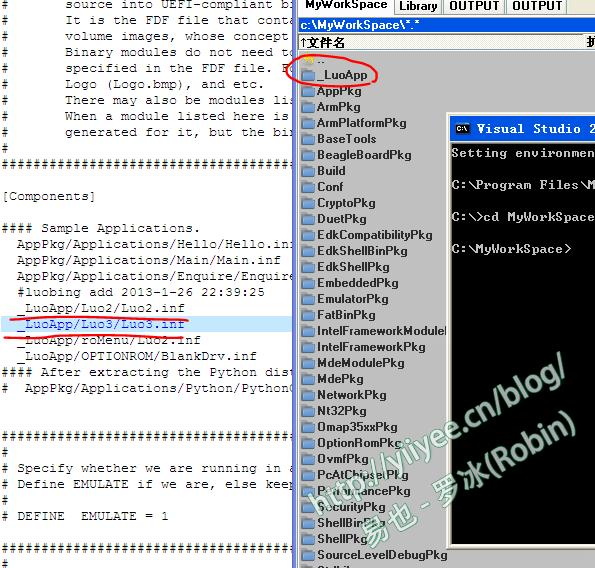
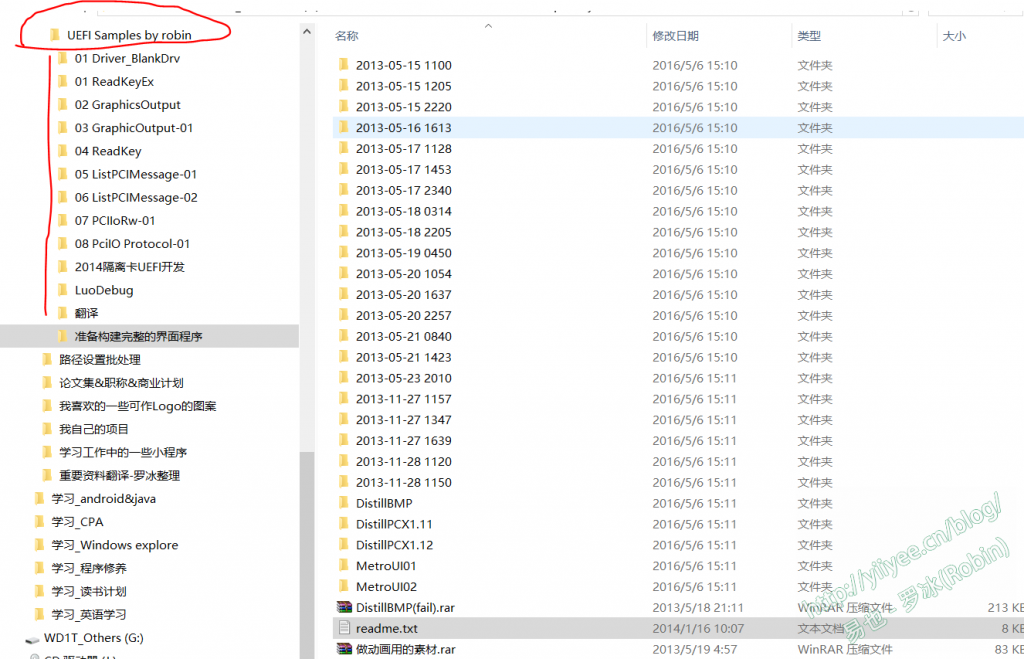
为方便后续的开发,我在根目录下建立了一个\_LuoApp的文件夹。在\AppPkg\AppPkg.dsc中添加相应的inf文件,指明要编译的代码,如图所示。
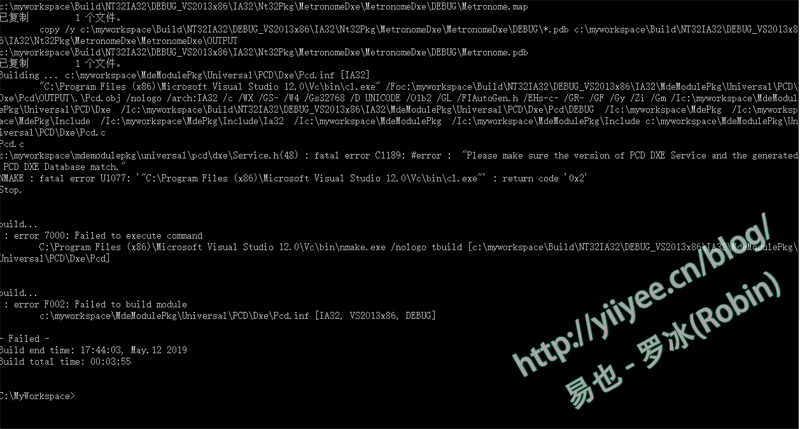
图3 建立编译用的目录 (20190512 20:13 Robin: 这次的编译仍旧使用了UDK2010的环境。我试图搭建UDK2017或UDK2018,都不成功。有的NT32Pkg可以编译,但是AppPkg无法编译通过;有的则连Nt32Pkg都编译不通过。VS2013和VS2015都试过了,怀疑是我VS版本有些问题。)
修改target.txt,设置为如下参数:
ACTIVE_PLATFORM = AppPkg/AppPkg.dsc
打开Visual Studio 2008 command,编译:
C:\MyEorkSPace>edksetup.bat
生成的文件为c:\myWorkSpace\Build\AppPkg\DEBUG_VS2008\IA32\_LuoApp\Luo2\Luo2\OUTPUT\Luo2.efi
将其拷贝至之前编译好的NT32下(主要是可以使用SecMain.exe):
c:\myWorkSpace\Build\NT32\DEBUG_VS2008\IA32\
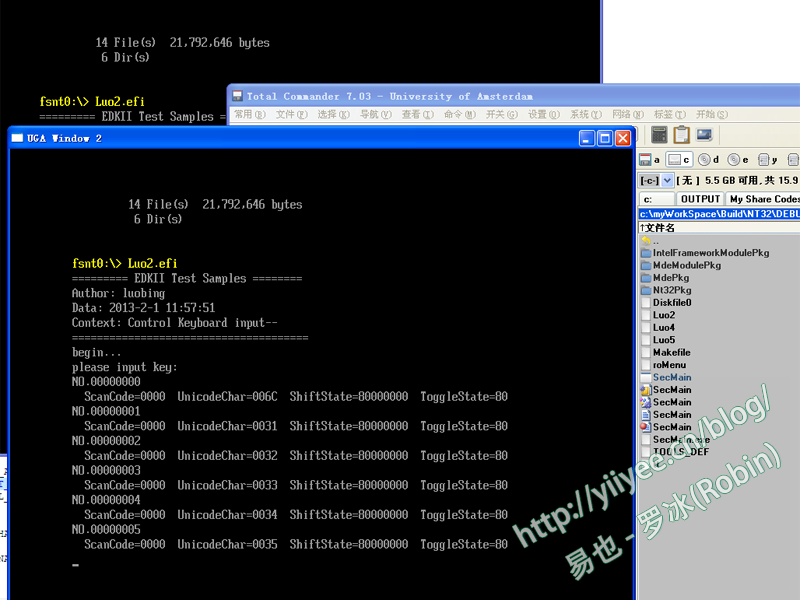
运行SecMain.exe,测试Luo2.exe:
图4 编译好的键盘处理程序 代码放在百度云上,对照看下,逻辑还是比较简单的,将用户的按键信息打印出来。这个程序是以main入口函数来编写的,另外也编写了一个UefiMain入口函数的程序,功能一样,也在云端。
至此,实现了键盘的访问。如需要在实际机器上运行,只要修改编译参数即可。
百度云链接:https://pan.baidu.com/s/1gccSosw8_UAGTI5gZPnLCA
键盘访问的代码在 01 ReadKeyEx下。