本文讨论设备性能的一般度量方法,并根据性能判断的基准点是否确定唯一,将设备性能分为外部性能和内部性能 两类。
外部性能
我们采用很多方法来量化一个设备的性能,一般是横向比较,也就是运行一些基准测试软件来获得针对指定设备的测试成绩,作为度量设备性能的量化数据。但是,如果只有单个设备的量化成绩,其实作用不大。100分的成绩,对应的性能到底为高、中或低,需要和更多的设备进行横向比较,才能体现出来。业界会针对某类设备,设立若干个性能相关的标杆基准点,来判别不同的量化分数所对应的性能级别。值得注意的是,这个所谓的标杆基准点,可能是有形的数字,但更可能是无形的,由一些评测实验室在他们的评测报告中体现,当一款新的旗舰设备隆重上市后,旧标杆将随之被修正。
换句话说,通过横向比较为来判断性能时,在不同的时间,比较和判断的标杆基准点很可能是不同的。如果你淘了一块心仪已久的两年前的旗舰显卡,欣欣然准备要大显身手的时候,重新评估一下这块显卡在今天的性能地位,发现已经掉档到入门级别了,你可能会大失所望吧。设备本身的性能并未改变,变化的是评判的标准。
硬件生产工艺的进步,会带来设备性能的大幅提升,特别是摩尔定律还在发生作用的年代,这个提升的幅度是指数级别的,非常惊人。影响性能成绩的另一个因素,是测试软件自身的代码演进和优化程度。一个并不罕见的情况是,使用不同的基准测试软件,对不同的设备进行测试,如果这些设备在市场上的目标定位相同,最后的测试成绩很可能互有参差,而不是一边倒地断定出孰优孰劣。在某个测试软件中,A产品领先一些,另一个测试软件中,B产品则略胜一筹。还有一种情况是,将某个基准测试软件版本升级之后,重新测试某产品,可能会发现结果大不相同。再比如,同一块显卡上,使用不同的3D编程接口(如OpenGL、DX或其它),在渲染相同的内容时,性能也可能不同。这是3D编程接口需要不断迭代升级的一个原因,如何通过优化自身的结构,来更好地发挥硬件的有限性能。
软件的编程方式和优化特性的选择,对不同的设备会产生不同的性能表现。
这种通过外部横向比较而产生的性能数据和判断依据,称为外部性能。其典型特征是:性能的判断依据不断变化——主要地,其性能基准点不断地被提高。
内部性能
较少受注意的是设备的内部性能,内部性能被定义为:使用指定的设备,不同的软件方案所发挥出来的设备效能的强弱。和外部性能相反,内部性能的典型特征是:性能的极限是已知的,即:物理设备满负荷不停工作所能达到的性能。内部性能永远小于或等于极限性能(内部性能 <= 极限性能)。
这里面有一个典型的案例,就是在多核系统上,一个设计为单线程的数据处理软件,和进行过多线程优化的数据处理软件,所能发挥的处理器性能,相差甚远。
忙碌度
如何量化内部性能呢?目前没有标准方案。我在这里提一个参考数据,称为设备的忙碌度。可以简单地作如下定义:
在采样时间t内,物理设备的工作时间为t1,空闲时间为t – t1。则设备在t时间内的: 忙碌度 = (100 * t1 / t)% 空闲度 = (100 * t - 100 * t1)%
上面的计算公式忽略了可能存在的频率变化的因素。很多设备有省电功能,在设备不需要保持忙碌状态的时候,将设备的工作频率降低甚至关闭,从而节约电能。重新恢复到高频需要一定的时间,会导致一定的性能下降。但我们假设所涉及的采样和计算是在同一个基准频率上进行的,且忽略这个因素。
在一些案例中,忙碌度可以很好地量化内部性能。回到前面多核处理器的例子,现在假设我们能够排除系统中其它软件的干扰,只对一个指定的数据处理软件进行性能采样和评估。在一个4核处理器的系统中,单线程软件的处理器忙碌度为90%,平均到4核心后整体忙碌度为22.5%。多线程优化过的软件,同时调动四个处理器核心进行运算,忙碌度分别为90%、80%、60%和50%,平均后的整体忙碌度为70%。这样我们大致看出来,后者的内部性能是前者的3倍多。
| 忙碌度 | 单线程软件 | 多线程软件 |
|---|---|---|
| Core1 | 90% | 90% |
| Core2 | 0 | 80% |
| Core3 | 0 | 60% |
| Core4 | 0 | 50% |
| 平均 | 22.5% | 70% |
Table1. 运行两种数据处理软件时的处理器忙碌度
忙碌度是有局限的。软件方案商的心里都很明白发挥设备的每一毫瓦电力为其所用所能带来的经济价值,所以会针对平台和设备进行各种优化,来令它尽可能地满负荷工作。不同的考核的软件,都能把设备忙碌度推向峰值或打成平手。这时,就软件性能而言,还需继续寻找其它的数据进行考核,忙碌度已无能为力。
设备虚拟化
忙碌度却可能很好地运用于设备虚拟化中,因为从原理上看,设备虚拟化所要做的事情,是把唯一的物理设备,分配给多个系统同时或分时使用,并尽可能地发挥物理设备的内部性能。但由于虚拟化总是会带来一定的软件开销,所以从理论上讲,任何设备虚拟化的方案,它的忙碌度总是无限接近于物理设备的峰值,而稍微低一点(虚拟性能 < 物理性能)。这样,哪个方案可以令工作时的整体忙碌度更接近于物理峰值,便是一个更好的方案。所以,忙碌度可以作为判断方案优劣的依据。
以GPU虚拟化为例
忙碌度运用在GPU虚拟化方案中,忙碌度越高,表示采样时间内的工作时间越长,处理的指令数越多,表现的性能也就越好。假设有两种GPU设备虚拟化方案,在同一个系统平台上,各创建两个虚拟设备,分配给两个虚拟机使用。两个虚拟机系统同时运行基准测试软件,得到的忙碌度结果如下:
| 忙碌度 | vGPU – 1 | vGPU – 2 | 物理GPU |
|---|---|---|---|
| 方案1 | 40% | 40% | 80% |
| 方案2 | 32% | 35% | 67% |
Table2. 不同GPU虚拟化方案的忙碌度
在运行基准软件的过程中,方案1的平均忙碌度是80%,方案2是67%。也就是说,方案1使得物理GPU多运行了13%的时间。所以,方案1发挥了更佳的内部性能。
GVT-G案例
以目前Linux主线中的Intel显卡虚拟化方案GVT-G为例(内核版本4.11.0,GPU型号Gen8 GT2),运行同一版本的基准软件glmark2,在非虚拟化环境下,GPU的忙碌度达到93%。
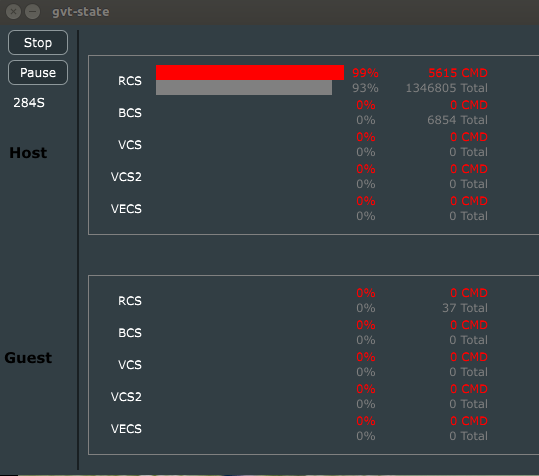
Picture1: GVT-G虚拟化中Dom0系统的GPU忙碌度
上图右侧有两个区域,上面的区域是物理GPU各个硬件引擎的状态,下面是虚拟系统(VM)所使用的虚拟GPU的各引擎的状态。其中,红色方块和数字表示实时数据,灰色方块和数据表示过去全部采样时间内的平均数据,上图中的全部采样时间是284秒。glmark2软件主要使用了3D引擎,所以看到只有RCS引擎在忙碌着,其它引擎都完全空闲。
切换到虚拟机,也运行glmark2软件,物理GPU的整体忙碌度为55%。其中51%的忙碌度是虚拟GPU(vGPU实例)贡献的,其余4%左右和Dom0系统产生的。
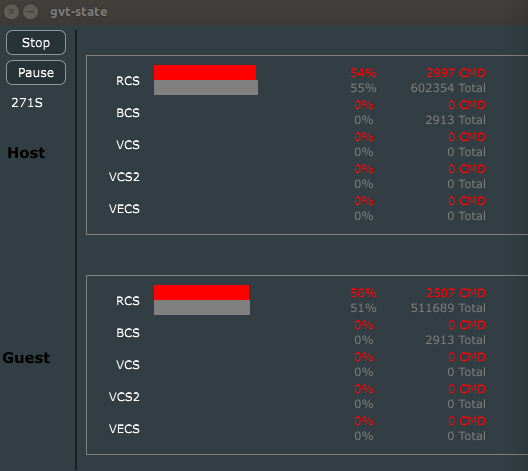
Picture2: GVT-G虚拟化中DomU系统的GPU忙碌度
glmark2是一个很典型的基准软件,它以频繁地提交小命令囊著称。在本例中,虚拟机在271秒的时间里,提交了511689个命令囊到硬件,平均每0.5毫秒提交和处理一个命令囊。对于这种频繁提交小命令囊的测试,虚拟化的开销在整体调度过程中,就相对地显得特别庞大。等待CPU完成MMIO的陷入模拟、命令扫描,以及执行一些调度策略。所有这些由CPU执行的任务,平均到每个命令囊,大概花费了0.2ms的时间,这导致GPU硬件有近一半的时间处于闲暇状态中。
同样的测试方法,换用PCMark、3DMark等软件测试,会发现虚拟GPU的忙碌度提升到80%以上,因为这些软件提交的命令囊较大,物理GPU平均需要2-4毫秒的时间才能处理完一个命令囊,GVT开销所占的整体比例就相应地下降到10%左右,从而提高了GPU的整体忙碌度超过80%。
通过采集和分析忙碌度,有针对地优化虚拟化方案,提高物理GPU的内部性能。可以说,忙碌度为评估和优化虚拟化方案,提供了一个很好的依据。
4,528 total views, 2 views today