请保留-> 【原文: https://blog.csdn.net/luobing4365 和 http://yiiyee.cn/blog/author/luobing/】
最近有个项目开发,我需要构建几个UEFI图形对话框,用来接受用户的密码修改和输入。大致的样子是这样的:
开发过程中,发现使用VS编译和GCC编译的结果不同。一番折腾后,了解到是强制转换引起的问题。
之前有个问题集的博客,本想把这个问题也扔到那边去,不过在寻找问题原因的过程中,使用了各种调试手段,我觉得有必要记录下来,作为未来开发的参考。
因此有了这篇博客。
1 问题代码
问题的来源,在于Linux下的UEFI代码中,不能使用UINT8 *的指针字符串,它只允许使用CHAR8 *型字符串。而我之前所有的代码,都是在Windows下开发的,大量的基础数据都是UINT8型,转到Linux下编译,就需要进行类型转换了。
出问题的代码如下:
示例1 摘自OpPWD/Font.c
VOID draw_string(CHAR8 *str, UINTN x, UINTN y, FONT_INFO *font, EFI_GRAPHICS_OUTPUT_BLT_PIXEL *font_color)
{
UINT8 temp;
UINT8 *ptr;
UINT32 char_utf8;
UINTN cur_x;
ptr = str;
cur_x = x;
while('\0' != *ptr)
{
//1 get utf-8 code from str
temp = (UINT8 )ptr[0];
if(temp > 128) //汉字
{
char_utf8 = (((UINT32)ptr[0]) << 16) + (((UINT32)ptr[1]) << 8) + (UINT32)ptr[2];
ptr += 3;
}
else
{
char_utf8 = (UINT32)ptr[0];
ptr += 1;
}
//2 display a char
cur_x += (UINTN)draw_single_char(char_utf8, cur_x, y, font, font_color);
}
}其功能很简单,将包含各种字符的字符串(包括中文、英文、各种符号)在屏幕上打印出来。问题出在char_utf8的赋值语句上,在Linux平台编译后,所得到的结果不是希望的结果。
为便于调试,原语句:
char_utf8 = (((UINT32)ptr[0]) << 16) + (((UINT32)ptr[1]) << 8) + (UINT32)ptr[2];改为了:
char_utf8 = (((UINT32)ptr[2]));
char_utf8 += (((UINT32)ptr[1]) << 8);
char_utf8 += (((UINT32)ptr[0]) << 16);2 Linux下编译调试
之前的博客中,介绍过Linux下使用UDK Debugger Tool搭建UEFI的调试平台,这里的步骤差不多,记录如下。
2.1 关闭优化选项
由于原始的编译选项,打开了优化开关,有些局部变量会被优化掉,不方便调试,需要将编译选项修改一下。
可在Conf/tools_def.txt中修改,把DEBUG相关的编译选项改成如下形式:
# DEBUG_GCC5_X64_CC_FLAGS = DEF(GCC5_X64_CC_FLAGS) -flto -DUSING_LTO -Os
DEBUG_GCC5_X64_CC_FLAGS = DEF(GCC5_X64_CC_FLAGS) -flto -DUSING_LTO -O0
# DEBUG_GCC5_X64_DLINK_FLAGS = DEF(GCC5_X64_DLINK_FLAGS) -flto -Os
DEBUG_GCC5_X64_DLINK_FLAGS = DEF(GCC5_X64_DLINK_FLAGS) -flto -O0 #close Optimization
gcc提供了5级优化选项的集合,包括:
-O0: 无优化 。
-O和-O1: 使用能减少目标文件大小以及执行时间并且不会使编译时间明显增加的优化;
-O2: 此选项将增加编译时间和目标文件的执行性能,包含-O1的优化并增加了不需要在目标文件大小和执行速度上进行折衷的优化,编译器不执行循环展开以及函数内联;
-Os: 专门优化目标文件大小,执行所有的不增加目标文件大小的-O2优化选项,并且执行专门减小目标文件大小的优化选项;
-O3: 打开所有-O2的优化选项并且增加 -finline-functions, -funswitch-loops,-fpredictive-commoning,-fgcse-after-reload and -ftree-vectorize优化选项。EDK2中原始的编译选项,使用了-Os进行优化。我们将其改为-O0,也即关闭所有优化,方便调试。
2.2 编译及启动调试
在需要调试的代码处,加入中断语句:
CpuBreakpoint();编译需要调试的程序:
robin@robin-virtual-machine:~/UEFIWorkspace$ source ./myexport.sh
robin@robin-virtual-machine:~/UEFIWorkspace$ source edk2/edksetup.sh
robin@robin-virtual-machine:~/UEFIWorkspace$ build -p edk2-libc/RobinPkg/RobinPkg.dsc -m edk2-libc/RobinPkg/Applications/OpPWD/OpPWD.inf -a X64 -t GCC5 -b DEBUG将生成的OpPWD.efi和OpPWD.debug拷贝到UDK调试用的文件夹had-contents。(UEFI开发探索39中有详细的步骤)
开终端1,启动UDK Debugger Tool:
robin@robin-virtual-machine:~$ sudo /opt/intel/udkdebugger/bin/udk-gdb-server开终端2,启动gdb:
robin@robin-virtual-machine:~$ gdb开终端3,启动qemu:
robin@robin-virtual-machine:~/UEFIWorkspace/_UDK_gdb$ qemu-system-x86_64 -pflash OVMF.fd -hda fat:rw:hda-contents -net none -debugcon file:debug.log -global isa-debugcon.iobase=0x402 -serial pipe:/tmp/serial在终端2的gdb中输入终端3所报的连接,一般是“Connect with ‘target remote
robin-virtual-machine:1234'”
(gdb) target remote robin-virtual-machine:1234'
(gdb) source /opt/intel/udkdebugger/script/udk_gdb_script
(udb) c
Continuing.Qemu将启动UEFI Shell,在Shell下进入FS0:\,并运行需要调试的程序:
FS0:\> OpPWD.efi终端2的udb将中断到之前条件的中断语句处,就可以进行调试了。
在本篇的问题中,第一个传入的汉字是“验”,其UTF8码为0xE9AA8C。调试中得到的信息如下:
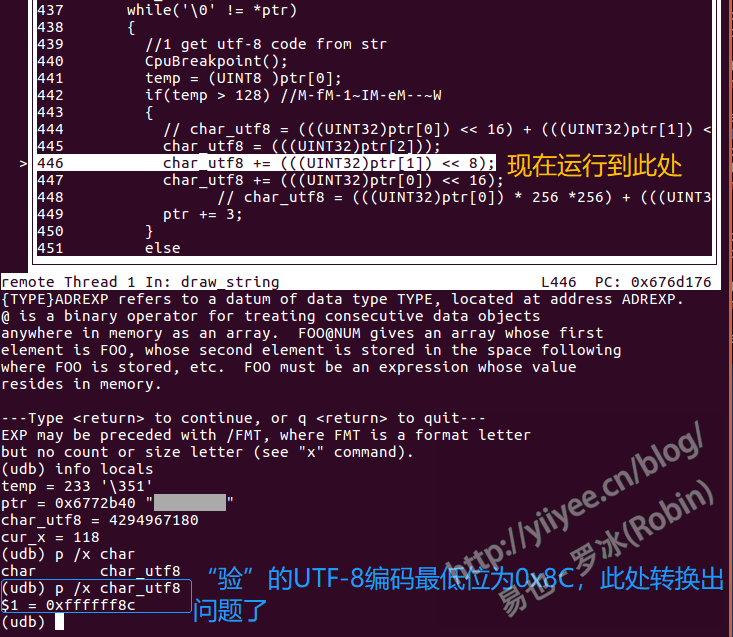
很明显看出,转换出了一个超大的数,不是预想的0x8C。后续程序运行,char_utf8的值不会是0xE9AA8C,也就无法定位字模库中对应的位置了,导致汉字字符无法显示。
3 Windows下编译调试
Windows下调试相对比较简单,直接使用VS2015配合SecMain.exe(或者WinHost.exe)就可以了。搭建的方法,在之前博客中也讨论过,这里不重复介绍了。
直接看调试结果。
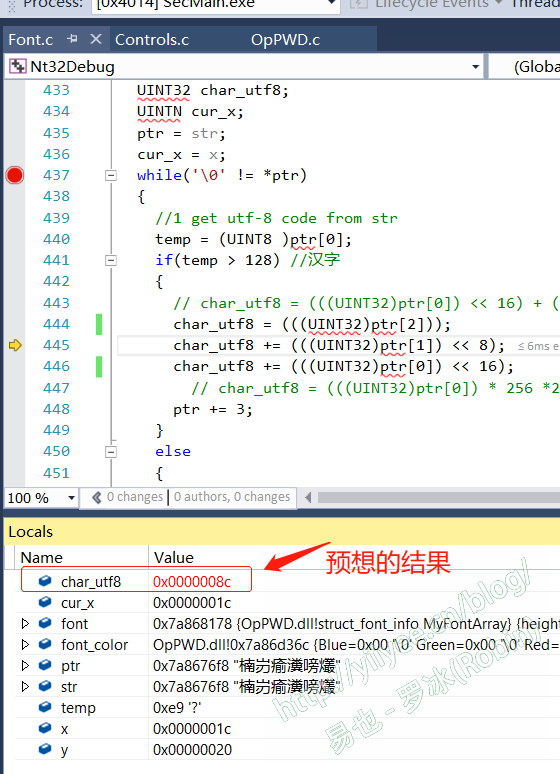
可以看出,在Windows下运行结果是对的。
4 问题分析
问题并不复杂,是由于类型转换导致的。而且由于编译器的不同,导致出现了不同的结果。也就是说,VS2015和gcc对类型转换的处理,采用的方式是不同的。
我手边有本常用的C语言的参考书,是比较经典的《C语言参考手册》第5版。在这本书的第6章151页处,有这样的描述:
“如果目标类型的长度大于原类型,则结果类型无法表示原值的唯一情况就是当负的有符号值转换为一种更长的无符号类型的时候。在这种情况下,转换行为必须就像首先把原值转换为与目标类型相同长度的有符号类型,然后再转换为目标类型一样。”
这翻译比较拗口,大致意思还是很容易明白的。
在本篇的问题代码中,ptr[2]的值为0xC8,需要转换为UINT32。则首先转换为INT32型的有符号数,然后再转换为UINT32型。因此,高位的负值就这么被保留下来了,这是在Linux的gcc编译之后出现问题的原因。
而Windows平台的VS2015,应该没有采用这种方式进行转换,因此才没有出现Linux平台同样的问题。
发现问题后,对代码进行简单调整就可以了。解决方法很多,就不再这里描述了。
2,426 total views, 2 views today